Quick Summary: Amazon Bedrock is a fully managed, serverless service from AWS that enables developers to build and scale generative AI applications using leading foundation models from providers like Anthropic, Meta, Mistral AI, and Amazon without managing infrastructure. It provides secure, enterprise-grade access to hundreds of AI models through a unified API, along with tools for customization, knowledge bases, agents, and guardrails.
Generative AI has shifted from experimental novelty to strategic necessity. According to recent industry data, 81% of executives now lead AI adoption initiatives, compared to just 53% last year. But enthusiasm crashes into reality when teams face infrastructure limitations, which 44% of companies identify as their primary obstacle.
Amazon Bedrock emerged as AWS’s answer to this challenge. Launched in 2023, it’s a fully managed platform that removes the infrastructure burden from building generative AI applications. Instead of provisioning servers, training models, or managing scaling, developers access leading foundation models through a unified API.
And it’s working. Amazon Bedrock powers generative AI for more than 100,000 organizations worldwide, from startups to global enterprises across every industry.
The Core Service: What Amazon Bedrock Actually Does
Amazon Bedrock is a Platform-as-a-Service (PaaS) offering that provides serverless access to foundation models. The service eliminates the traditional barriers to AI deployment: expensive infrastructure, model training expertise, and scaling complexity.
Here’s the thing though—Bedrock isn’t about building models from scratch. It’s about accessing pre-trained, state-of-the-art models and customizing them for specific business needs. Developers submit prompts and generate responses using model inference operations without ever touching server configurations.
The platform supports multiple modalities. Text generation, image creation, multimodal embeddings, and code generation all run through the same unified interface. This consistency matters when teams need to swap models without rewriting entire applications.
Fully Managed and Serverless Architecture
Bedrock handles automatic scaling behind the scenes. When application traffic spikes, the service provisions additional capacity. When usage drops, resources scale down. No manual intervention required.
This serverless model means teams pay only for actual usage. There’s no cost for idle infrastructure sitting around waiting for requests. According to official AWS documentation, the service integrates directly with other AWS offerings like S3 and SageMaker through standard APIs.
Foundation Models: The Model Selection Advantage
Model choice sits at the heart of Bedrock’s value proposition. The platform provides access to hundreds of foundation models from leading AI providers, and the ability to swap them without rewriting code transforms model selection from a technical constraint into a strategic advantage.
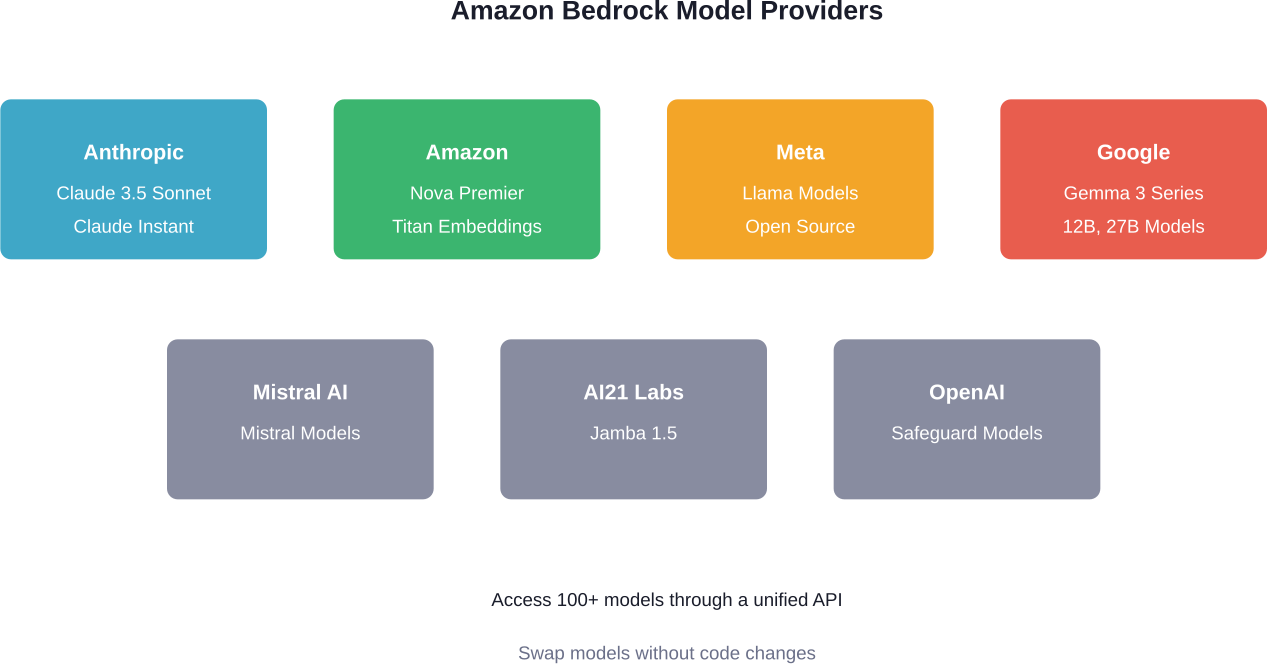
Current supported providers include Anthropic (Claude models), Amazon (Nova and Titan series), Meta (Llama), Google (Gemma 3), Mistral AI, AI21 Labs (Jamba), OpenAI, and Qwen. Each provider brings different strengths. Claude 3.5 Sonnet excels at complex reasoning. Nova Premier handles multimodal tasks. Titan Embeddings optimize for semantic search.
The built-in evaluation tools help teams compare performance, cost, and accuracy across models. This turns model selection from guesswork into data-driven decision-making.
Pricing Structure: How Amazon Bedrock Charges
Bedrock uses token-based pricing with multiple service tiers. Costs depend on the specific model provider, modality, and service tier selected.
As of March 2026, the official pricing page shows several tiers:
- Standard Tier: Base pricing for on-demand inference
- Flex Tier: Optimized price-performance for specific use cases
- Priority Tier: Standard rate plus premium for faster processing (up to 25% better latency)
- Reserved Tier: Commitment-based pricing for predictable workloads
Batch inference offers a 50% discount compared to on-demand pricing for select foundation models. Pricing is calculated per 1 million tokens for both input and output.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Claude Instant 1.2 | $0.0008 per 1K tokens input and $0.0024 per 1K tokens output (or $0.80 and $2.40 per million tokens) | $0.0008 per 1K tokens input and $0.0024 per 1K tokens output (or $0.80 and $2.40 per million tokens) |
| Claude 2.1 | $8.00 | $24.00 |
| Gemma 3 4B | $0.04 | $0.08 |
| Gemma 3 12B | $0.09 | $0.29 |
The official pricing page notes that rates vary by AWS region. US East (Virginia), US East (Ohio), and US West (Oregon) typically offer the most competitive pricing. Cache read and write operations carry separate charges for models that support prompt caching.
Key Capabilities That Differentiate Bedrock
Knowledge Bases
Knowledge Bases let applications connect foundation models to proprietary data sources. The service handles the entire Retrieval-Augmented Generation (RAG) workflow: ingesting documents from S3, creating vector embeddings, storing them in vector databases, and retrieving relevant context for prompts.
This capability transforms generic AI responses into answers grounded in specific company data, policies, or technical documentation.
Agents
Bedrock Agents orchestrate multi-step tasks by breaking down user requests, invoking APIs, and executing actions. An agent can book appointments, query databases, and perform calculations—all through natural language instructions.
Agents represent a shift from simple question-answering to autonomous task execution. They extend what generative AI can accomplish without custom orchestration code.
Guardrails
Guardrails enforce safety policies on model inputs and outputs. Teams configure content filters, topic restrictions, and sensitive information redaction without modifying application code.
This matters for regulated industries. Financial services, healthcare, and government applications need to prevent models from generating inappropriate content or leaking protected data. Guardrails provide that control layer.
Model Customization
Fine-tuning capabilities let teams adapt foundation models using their own datasets. This improves performance for domain-specific tasks without training models from scratch.
Customization maintains the serverless model. Teams upload training data, configure hyperparameters, and Bedrock handles the rest.
Amazon Bedrock vs Competitors
The generative AI platform market centers on three major players: Amazon Bedrock, Azure OpenAI Service, and Google Vertex AI. Each takes a different approach.
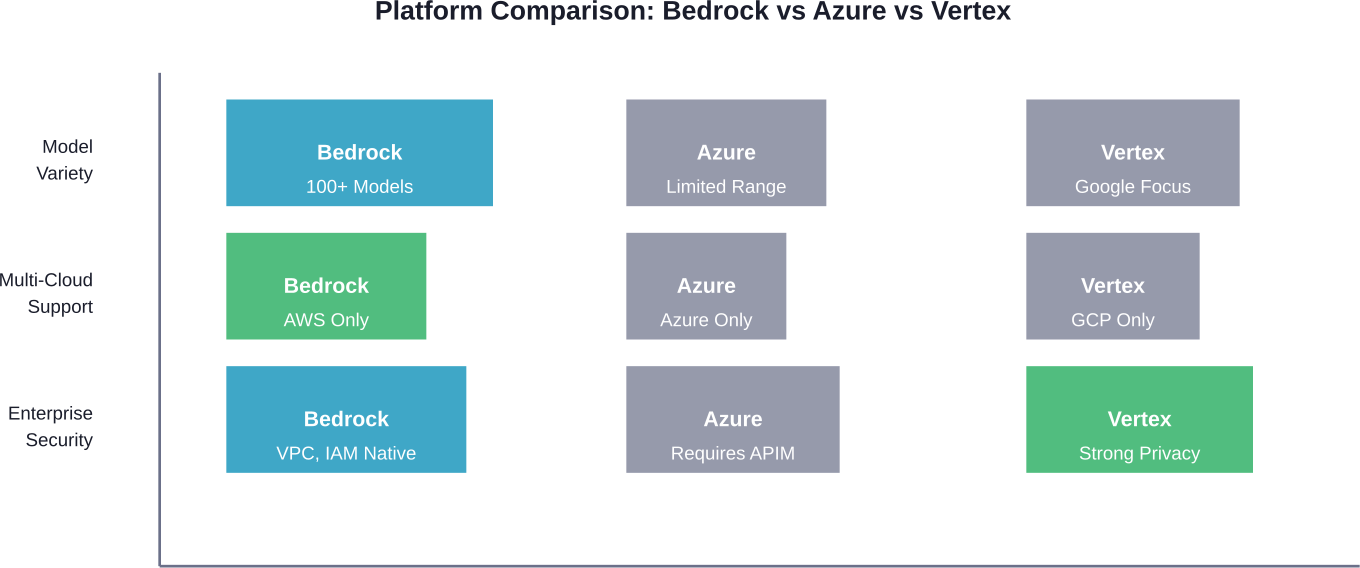
Bedrock emphasizes model diversity. Azure OpenAI focuses heavily on OpenAI models (GPT-4, GPT-3.5) with limited alternatives. Google Vertex AI naturally prioritizes Google’s own models like PaLM and Gemini.
The integration story differs too. Bedrock connects natively to AWS services—S3, Lambda, IAM, CloudWatch. Azure OpenAI integrates with Microsoft’s ecosystem. Vertex AI works best within Google Cloud Platform.
Security architectures reflect platform philosophies. Bedrock uses VPC endpoints and IAM roles without additional gateway services. Azure implementations often require API Management (APIM) for VNET integration, which adds hourly costs and data processing fees.
Real talk: Nearly 74% of organizations now use cloud-based AI platforms to reduce infrastructure costs and optimize resources. Platform lock-in remains a concern, but multi-cloud AI strategies remain complex.
Real-World Applications and Use Cases
Amazon Bedrock supports diverse generative AI applications across industries. Customer service chatbots use Claude models for nuanced conversation handling. Content generation systems leverage multiple models to create marketing copy, product descriptions, and technical documentation.
Code generation represents another major use case. Development teams use Bedrock to auto-generate boilerplate code, write unit tests, and explain complex codebases in natural language.
Document processing applications combine Knowledge Bases with foundation models to extract insights from contracts, financial reports, and legal documents. The RAG architecture grounds responses in actual document content rather than model hallucinations.
According to AWS, companies like Robinhood and Epsilon leverage Bedrock for production AI applications. The service handles customer-facing workloads where latency and reliability directly impact business outcomes.

See How Amazon Data Is Actually Used In Practice
Amazon Bedrock explains how AWS handles large-scale data and AI models behind the scenes. But on the marketplace side, most decisions still come down to simpler data – ads, clicks, and sales, and how they connect. WisePPC works with that layer.
It takes Amazon ads and sales data and brings it into one place so you can see performance without piecing reports together. You can follow how campaigns change over time, compare results, and adjust bids or budgets directly, all based on the same dataset rather than separate views. Explore WisePPC to see how Amazon data is used in day-to-day decisions.
![]()
Getting Started: First Steps With Bedrock
AWS provides a quickstart path for new Bedrock users. The console offers a web interface for testing models without writing code. Teams can submit prompts, compare outputs across models, and evaluate performance before committing to API integration.
For programmatic access, the Bedrock API supports standard AWS SDK libraries across multiple languages—Python, JavaScript, Java, Go, C++. Authentication uses IAM credentials, the same identity system as other AWS services.
Model access requires explicit enablement. Not all foundation models are available by default. Teams request access through the Bedrock console, and AWS provisions capacity based on availability and account standing.
The official documentation includes code examples for common operations: invoking models, streaming responses, managing conversations, and implementing RAG workflows. These examples accelerate initial development.
Limitations and Considerations
Amazon Bedrock operates exclusively within AWS infrastructure. Teams committed to multi-cloud strategies or already invested in Azure or GCP face migration challenges. The service doesn’t offer portable deployment options.
Regional availability varies. Not all models are accessible in all AWS regions. Pricing differences across regions can impact cost optimization strategies. Teams should verify model availability in their preferred deployment region before architectural planning.
Model capacity constraints occasionally occur during high-demand periods. Priority tier helps, but even premium service levels can’t guarantee instant availability during extreme usage spikes. Enterprise customers sometimes wait weeks for capacity approval in specific regions.
Fine-tuning capabilities exist but don’t match the depth of custom training on dedicated infrastructure. Teams with highly specialized requirements may hit limitations in model customization depth.
Frequently Asked Questions
What exactly is Amazon Bedrock used for?
Amazon Bedrock is used to build generative AI applications like chatbots, content generators, document analyzers, and code assistants without managing infrastructure.
How much does Amazon Bedrock cost?
Pricing is token-based and varies by model. Costs depend on input/output tokens and the chosen provider, with discounts available for batch processing.
What models are available in Amazon Bedrock?
Bedrock offers models from providers like Anthropic, Amazon, Meta, Google, Mistral, and others, with availability depending on region.
Is Amazon Bedrock the same as AWS SageMaker?
No, SageMaker focuses on custom model training, while Bedrock provides serverless access to pre-trained models for faster deployment.
Can Amazon Bedrock work with my private data?
Yes, it can connect to private data sources like S3 while keeping data secure within your AWS account.
What industries use Amazon Bedrock?
Industries include finance, healthcare, retail, media, software development, and government.
Does Amazon Bedrock support fine-tuning?
Yes, certain models support fine-tuning to customize outputs using your own data.
Final Thoughts
Amazon Bedrock eliminates traditional barriers to generative AI adoption. The fully managed, serverless architecture lets teams focus on application logic rather than infrastructure management. Access to hundreds of leading foundation models through a unified API provides flexibility as AI technology evolves.
But the platform lives within AWS. Multi-cloud strategies require additional architecture layers. Regional limitations and capacity constraints can slow deployments. Teams should evaluate these trade-offs against the operational simplicity Bedrock provides.
For organizations already committed to AWS infrastructure, Bedrock offers the fastest path from AI experimentation to production deployment. The combination of model diversity, enterprise security, and AWS service integration creates a compelling platform for scaling generative AI applications.
Ready to build with generative AI? Start exploring Amazon Bedrock through the AWS console, test models for specific use cases, and evaluate how the platform fits existing workflows. The official documentation and quickstart guides provide clear onboarding paths for teams at any experience level.
 No credit card required
No credit card required