How to A/B Test Your Products the Right Way
A/B testing sounds technical at first, but at its core it is simply a way to stop guessing and start learning from real customer behavior. Instead of changing something and hoping it works, you compare two versions and let the data tell you what actually improves performance. Sometimes the difference is obvious. Other times the results surprise you, and that is usually where the real insight lives.
For product teams and sellers, testing becomes less about chasing quick wins and more about building confidence in decisions. A small change to an image, title, or message can shift how people respond, but without testing it is almost impossible to know why. A structured A/B testing approach helps reduce risk, uncover patterns in customer behavior, and gradually improve results over time without disrupting what already works.
What A/B Testing Really Means in Practice
In everyday work, A/B testing is less complicated than it sounds. At its simplest, it is a controlled experiment designed to answer one question: which version works better for real users. Instead of changing something for everyone at once, you create two versions of the same element and split your audience between them. One group sees the original version, often called the control, while the other sees a modified version, known as the variant. Everything else stays the same so that the impact of the single change can be observed clearly.
What makes this approach reliable is that it removes opinion from the process. Teams often make decisions based on experience, preferences, or internal discussions, but customers do not always respond the way we expect. A product image that looks cleaner to a designer might feel less trustworthy to a buyer. A shorter description might seem easier to read but leave important questions unanswered. A/B testing replaces assumptions with observable behavior. Users vote through their actions rather than their feedback.
Another important detail is that A/B testing is not about guessing the winner in advance. It is about creating a fair comparison. Traffic is usually divided randomly so that each version is exposed to similar types of users. Over time, patterns emerge. If one version consistently leads to more clicks, purchases, or engagement, the difference is unlikely to be accidental. That is when teams can make changes with confidence instead of hope.
Why Product A/B Testing Matters More Than Ever
Products no longer compete only on features or price. They compete on clarity, trust, and how quickly users understand value. In an environment where customer attention is short and expectations change constantly, small improvements can make a noticeable difference, which is exactly why structured testing has become essential rather than optional.
Changing Digital Environments Require Continuous Validation
Digital environments do not stand still. Customer expectations shift quickly, competitors adapt, and platforms evolve. A product page that performed well last year may quietly lose effectiveness without anyone noticing immediately. Small declines compound over time, and performance rarely drops all at once. More often, it fades gradually as user expectations change. A/B testing helps detect and correct these slow shifts before they become larger problems.
A/B Testing Prevents Stagnation and Encourages Progress
A/B testing acts as a safeguard against stagnation. Instead of waiting for performance drops, teams actively explore improvements through controlled experiments. This proactive approach creates momentum because optimization becomes part of regular work rather than an occasional redesign effort. Even minor gains matter. When small improvements are applied consistently across product images, messaging, layout, or pricing presentation, the cumulative effect can be significant over time.
Data Reduces Friction in Team Decision Making
There is also a psychological benefit inside teams that often goes unnoticed. Testing reduces friction in decision making. Discussions move away from personal taste and toward measurable outcomes. When data replaces debate, progress tends to accelerate because decisions no longer depend on hierarchy or opinion. Teams spend less time arguing about direction and more time refining what actually works for users.
What You Should Test First
When people first discover A/B testing, there is often a temptation to test everything at once. Colors, fonts, layouts, messaging, imagery. The result is usually noise rather than insight. Prioritization matters more than experimentation volume.
A good starting point is to look at moments where customers make decisions. These are points where uncertainty or hesitation can stop progress. The closer an element is to that decision moment, the higher its testing value.
High Impact Elements to Consider
- Main product images or hero visuals
- Product titles and value propositions
- Pricing presentation or discounts
- Call to action wording or placement
- Key benefit descriptions
- Social proof such as reviews or testimonials
These elements shape first impressions and influence trust. Visual polish matters, but clarity matters more. Customers need to understand what the product is, why it matters, and what to do next. Testing helps refine that path.

WisePPC: Advanced Analytics to Guide Your Product A/B Testing Strategy
At WisePPC, we see A/B testing as a natural extension of analytics. Testing only works when you clearly understand what is happening before and after a change. That is why our platform focuses on giving sellers full visibility into both advertising and sales performance in one place. When you run experiments on product listings, pricing, or campaign structure, you need to see how those changes affect real outcomes, not just surface metrics. By combining historical data, real time performance tracking, and detailed segmentation, we help identify whether a variation genuinely improves results or simply shifts numbers temporarily.
In practice, this means we allow teams to compare performance across campaigns, placements, and time periods without losing context. Long term historical data helps avoid common testing mistakes, such as judging results too early or missing seasonal patterns. Granular analytics and filtering make it easier to isolate what changed and why, while bulk actions allow quick adjustments once a winning version is identified. Instead of guessing which version performs better, we focus on helping sellers connect testing decisions with measurable business impact, whether that is improved ROAS, reduced wasted ad spend, or clearer understanding of what actually drives conversions.
![]()
How to Run an A/B Test Without Guesswork
A/B testing works best when it follows a clear sequence. Many teams jump straight into creating variations because that feels like progress. In reality, most failed tests happen before the experiment even starts. The difference between useful results and confusing data usually comes down to preparation, clarity, and patience.
This section walks through the full process in a practical way. Each step builds on the previous one, so skipping ahead often creates more problems later.
Step 1 – Define What Success Actually Means
Before changing anything, it is important to understand why the test exists in the first place. A/B testing without a clear objective turns into activity without direction. You might end up with data, but no real answer.
A strong testing goal connects directly to user behavior. Instead of vague intentions like improving performance, the goal should describe a specific outcome you want to influence. For example, more completed purchases, higher engagement with product details, or fewer users dropping off before checkout.
What a Clear Goal Usually Answers
- What user action are we trying to improve
- Where in the journey the problem occurs
- How success will be measured
When goals are clear, analysis becomes simpler later. You already know which metric matters most and why you are measuring it.
Examples of Focused Testing Goals
- Increase product purchase rate by improving product clarity
- Improve click through rate on the primary call to action
- Reduce cart abandonment during checkout
- Increase engagement with key product information
The clearer the goal, the easier it becomes to design a meaningful test.
Step 2 – Turn Observations Into a Testable Hypothesis
Once the goal is defined, the next step is explaining why a change might work in the first place. This is where many tests either become meaningful or turn into random experimentation. A hypothesis gives the test direction. It connects what you are seeing in the data with a specific change you believe could improve the outcome.
A hypothesis is not a guess or a creative idea. It is a structured assumption built on observation. Something in the current experience is not working as expected, and the hypothesis explains what might be causing that friction. For example, if users consistently leave a product page within a few seconds, the problem may not be the price or the design. It could simply be that visitors do not immediately understand why the product matters to them. In that case, the hypothesis might be that improving the clarity of the headline or opening message will help users stay longer and engage more deeply.
The most useful hypotheses usually come from patterns rather than opinions. Customer reviews often reveal confusion or missing information. Support questions highlight areas where expectations do not match reality. Analytics can show where users hesitate or abandon the process altogether. Even comparing high performing products with weaker ones can reveal differences in messaging or presentation that are worth testing. These signals help turn testing into problem solving instead of experimentation for its own sake. Keeping the hypothesis focused is important. Each test should aim to answer one meaningful question. When the scope stays narrow, the result becomes easier to interpret, and the insight gained can be applied confidently to future improvements.
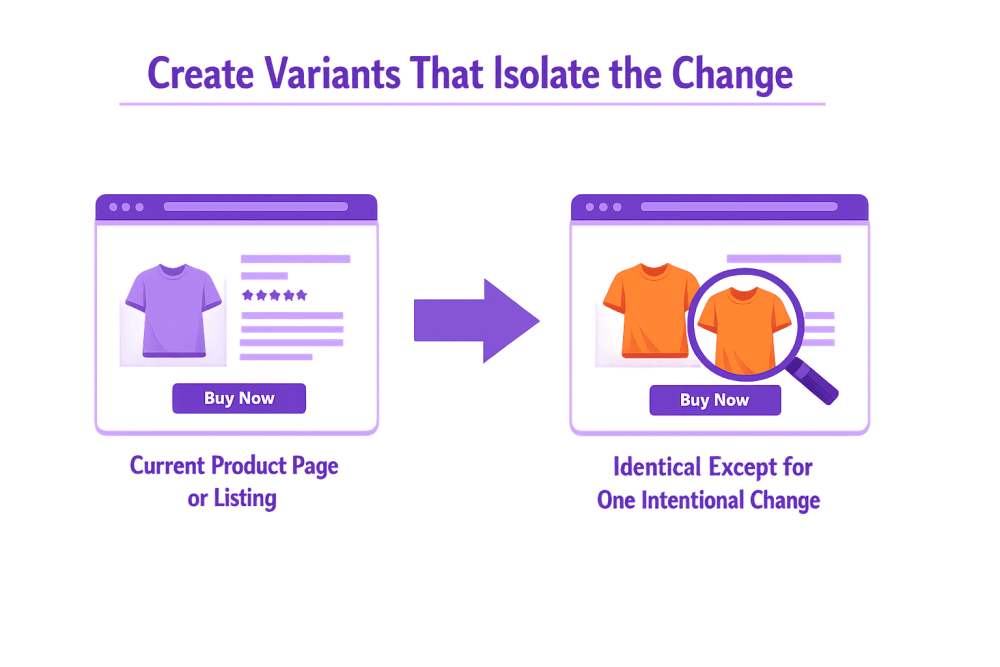
Step 3 – Create Variants That Isolate the Change
This is the stage where many A/B tests quietly lose their value. When several improvements feel obvious, the natural instinct is to update everything at once. A new image, rewritten copy, adjusted layout, maybe even pricing changes. The problem is that once multiple elements change together, the results stop being clear. If performance improves, you cannot confidently explain why it happened.
A well structured A/B test keeps things intentionally simple. The purpose is not to redesign the entire experience but to isolate one meaningful difference between two versions. When only one variable changes, cause and effect become visible. The outcome becomes useful knowledge rather than a lucky result.
Control Version – the Current Product Page or Listing
The control version is the existing version that users already see. It serves as the baseline for comparison because its performance is already known. Nothing is changed here. Keeping the control untouched ensures that any difference in performance comes from the new variation rather than external factors.
Variant Version – Identical Except for One Intentional Change
The variant version introduces a single, deliberate adjustment based on the hypothesis. This could be a different product image, revised headline wording, or a new placement for social proof. Everything else remains the same so the impact of that one change can be measured accurately. Maintaining this consistency protects the integrity of the test and makes the result easier to interpret.
When variants are created this way, the insight gained becomes reusable. A successful change can often be applied across other products or pages because you understand what influenced user behavior, not just that performance increased.
Step 4 – Let the Test Run Long Enough to Be Trustworthy
One of the hardest parts of A/B testing is waiting. Early data often looks convincing, especially when one version starts outperforming the other quickly. Unfortunately, early trends are often temporary.
User behavior changes depending on timing, traffic sources, and even day of the week. A version that performs well during a short window may not perform the same way over time.
Reasons tests need time:
- Weekday and weekend behavior differs
- New and returning visitors behave differently
- Campaign traffic fluctuates
- Random variation can create short term spikes
Ending a test too early introduces risk. A decision made on incomplete data can lock in a weaker version and undo previous improvements. Patience protects against this.
Step 5 – Look Beyond a Single Metric
It is natural to focus on the primary metric tied to the goal. However, real performance is rarely one dimensional. Improvements in one area can create unexpected tradeoffs elsewhere.
For example, a more aggressive message might increase clicks while reducing purchase quality. Engagement rises, but long term value drops. Looking at supporting metrics helps reveal these situations before changes are rolled out broadly.
Metrics Worth Reviewing Alongside the Main Goal
- Conversion rate
- Revenue per visitor
- Add to cart behavior
- Time spent on page
- Bounce or exit rates
- Customer quality indicators
A balanced analysis considers both engagement signals and business outcomes. The best performing version is not always the one with the highest clicks. It is the one that supports sustainable results.
Common A/B Testing Mistakes to Avoid
Most A/B testing problems do not come from bad intentions or lack of effort. They usually appear when teams move too quickly or try to force conclusions before the data is ready. Testing feels simple on the surface, but small mistakes in setup or interpretation can lead to decisions that quietly hurt performance instead of improving it. Understanding where things typically go wrong helps keep experiments useful and reliable.
Testing Too Many Changes at Once
This is probably the most common issue, especially when teams are eager to improve results quickly. Several elements look weak, so everything gets updated at the same time. The page looks better, performance changes, and everyone assumes the test worked. The problem is that no one knows which change actually made the difference.
When multiple variables move together, the result becomes impossible to learn from. You may accidentally keep changes that hurt performance while removing the ones that helped. Over time, this creates inconsistent results and makes future testing harder.
A/B testing works best when each experiment answers one clear question. One change, one comparison, one conclusion.
Ending Tests Too Early
Early data can be convincing. A variant shows improvement after a few days and the temptation to declare a winner becomes strong. The issue is that early results are often unstable. Traffic patterns change throughout the week, campaigns shift, and user behavior varies depending on timing.
Stopping a test too soon increases the chance of choosing a false winner. What looks like improvement may simply be short term fluctuation. Allowing enough time for behavior to normalize helps ensure the result reflects real performance rather than coincidence.
Patience here is not wasted time. It protects you from rolling out changes that later need to be reversed.

Optimizing for the Wrong Metric
Not every improvement is actually an improvement. Sometimes a test increases activity without improving outcomes that matter to the business. For example, a more aggressive message might increase clicks while attracting less serious buyers, leading to lower overall revenue or retention.
This usually happens when teams focus on easy metrics instead of meaningful ones. Metrics should always connect back to the real goal of the product or campaign.
Common examples include:
- Increasing click through rate while purchase rate declines
- Improving add to cart numbers without improving completed orders
- Reducing form friction but lowering lead quality
- Increasing engagement time without increasing conversions
Looking at supporting metrics alongside the primary goal helps prevent these situations.
Assuming One Result Fits Every Audience
Another frequent mistake is assuming that one winning version works equally well for everyone. In reality, different audience segments often behave differently. New visitors may need more explanation, while returning customers prefer speed and familiarity. Mobile users may respond differently than desktop users.
Ignoring these differences can hide valuable insights. Sometimes a losing variant overall performs exceptionally well for a specific segment. Recognizing these patterns can lead to more targeted improvements instead of one universal change.
Conclusion
A/B testing is often described as a tactic, but in practice it becomes a way of thinking about improvement. Instead of making changes based on instinct or internal debate, you give real users a voice in the decision. Sometimes the results confirm what you expected. Other times they challenge assumptions you did not even realize you were making. Both outcomes move the product forward.
What matters most is consistency. One test will not transform performance overnight, and that is perfectly normal. The real value appears over time as small insights accumulate. You begin to understand how customers interpret your messaging, what builds confidence, and where friction appears in the buying process. Decisions become calmer, changes become safer, and progress becomes more predictable.
If there is one thing worth remembering, it is that testing is not about chasing perfection. Products evolve, audiences change, and new ideas always appear. A/B testing simply gives you a reliable way to adapt without guessing. Start with a clear question, test it honestly, and let the results guide the next step.
FAQ
How long should an A/B test run before choosing a winner?
There is no universal timeline because it depends on traffic volume and the number of conversions generated. In general, a test should run long enough to capture normal user behavior across different days and traffic patterns. Ending a test too early often leads to misleading conclusions, so it is better to wait until results stabilize rather than reacting to early trends.
Can small changes really make a difference in A/B testing?
Yes, and this is often where surprising improvements come from. A different image, clearer headline, or better placement of key information can change how quickly users understand a product. These changes may look minor internally but can significantly affect how customers make decisions.
What should I test first if I am new to A/B testing?
It usually makes sense to start with elements that directly influence buying decisions. Product images, value propositions, and calls to action tend to have a stronger impact than purely visual adjustments. Testing areas closest to conversion helps produce clearer results early on.
Is it possible for an A/B test to fail?
Absolutely, and that does not mean the test was wasted. A result that shows no improvement still provides information. It tells you that a particular assumption was incorrect, which prevents larger mistakes later. Over time, these learnings help refine future experiments.
Do I need special tools to run A/B tests effectively?
Tools help with tracking and analysis, especially as testing becomes more frequent, but the core idea does not depend on complex software. What matters most is having clear goals, isolating changes properly, and analyzing results carefully. Technology supports the process, but discipline makes it work.
Join the WisePPC Beta and Get Exclusive Access Benefits
WisePPC is now in beta — and we’re inviting a limited number of early users to join. As a beta tester, you'll get free access, lifetime perks, and a chance to help shape the product — from an Amazon Ads Verified Partner you can trust.
 No credit card required
Free in beta and free extra month free after release
25% off for life — limited beta offer
Access metrics Amazon Ads won’t show you
Be part of shaping the product with your feedback
No credit card required
Free in beta and free extra month free after release
25% off for life — limited beta offer
Access metrics Amazon Ads won’t show you
Be part of shaping the product with your feedback
