Resumo rápido: O Amazon Bedrock é um serviço sem servidor e totalmente gerido da AWS que permite aos programadores criar e escalar aplicações de IA generativas utilizando modelos de base líderes de fornecedores como Anthropic, Meta, Mistral AI e Amazon sem gerir infra-estruturas. Fornece acesso seguro e de nível empresarial a centenas de modelos de IA através de uma API unificada, juntamente com ferramentas para personalização, bases de conhecimento, agentes e guardrails.
A IA generativa passou de novidade experimental a necessidade estratégica. De acordo com dados recentes do sector, 81% dos executivos lideram agora iniciativas de adoção de IA, em comparação com apenas 53% no ano passado. No entanto, o entusiasmo torna-se realidade quando as equipas se deparam com limitações de infraestrutura, que 44% das empresas identificam como o seu principal obstáculo.
O Amazon Bedrock surgiu como a resposta da AWS a esse desafio. Lançada em 2023, é uma plataforma totalmente gerenciada que remove a carga de infraestrutura da criação de aplicativos de IA generativos. Em vez de provisionar servidores, modelos de treinamento ou gerenciar o dimensionamento, os desenvolvedores acessam os principais modelos de base por meio de uma API unificada.
E está a funcionar. O Amazon Bedrock potencia a IA generativa para mais de 100.000 organizações em todo o mundo, desde startups a empresas globais em todos os sectores.
O serviço principal: O que o Amazon Bedrock realmente faz
O Amazon Bedrock é uma oferta de Plataforma como Serviço (PaaS) que fornece acesso sem servidor a modelos de fundação. O serviço elimina as barreiras tradicionais à implantação de IA: infraestrutura cara, experiência em treinamento de modelos e complexidade de dimensionamento.
No entanto, a questão é a seguinte: o Bedrock não se trata de construir modelos a partir do zero. Trata-se de aceder a modelos pré-treinados e de última geração e personalizá-los para necessidades comerciais específicas. Os programadores enviam pedidos e geram respostas utilizando operações de inferência de modelos sem nunca tocarem nas configurações do servidor.
A plataforma suporta múltiplas modalidades. A geração de texto, a criação de imagens, as incorporações multimodais e a geração de código são executadas através da mesma interface unificada. Esta consistência é importante quando as equipas precisam de trocar modelos sem reescrever aplicações inteiras.
Arquitetura totalmente gerida e sem servidor
O Bedrock lida com o escalonamento automático nos bastidores. Quando o tráfego da aplicação aumenta, o serviço fornece capacidade adicional. Quando o uso cai, os recursos são reduzidos. Não é necessária nenhuma intervenção manual.
Este modelo sem servidor significa que as equipas pagam apenas pela utilização real. Não há custos de infraestrutura ociosa à espera de pedidos. De acordo com a documentação oficial da AWS, o serviço se integra diretamente a outras ofertas da AWS, como S3 e SageMaker, por meio de APIs padrão.
Modelos de fundação: A vantagem da seleção de modelos
A escolha do modelo está no centro da proposta de valor da Bedrock. A plataforma fornece acesso a centenas de modelos de base dos principais fornecedores de IA, e a capacidade de os trocar sem reescrever o código transforma a seleção de modelos de uma restrição técnica numa vantagem estratégica.
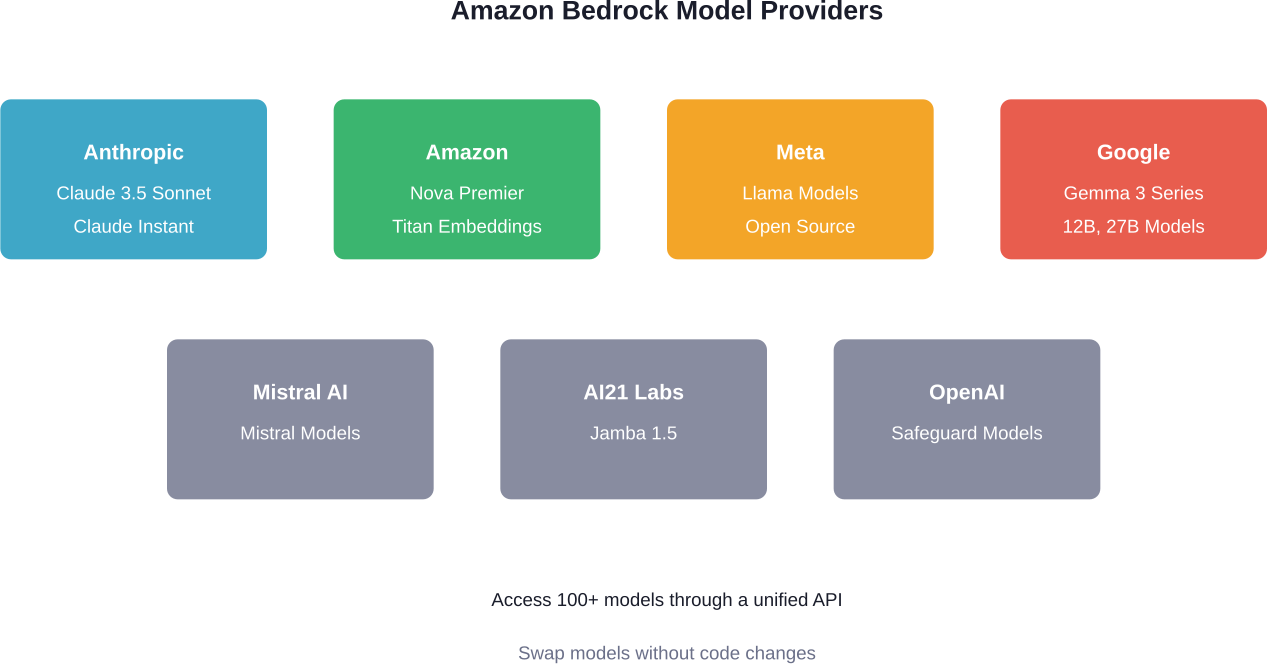
Os fornecedores atualmente apoiados incluem Anthropic (modelos Claude), Amazon (séries Nova e Titan), Meta (Llama), Google (Gemma 3), Mistral AI, AI21 Labs (Jamba), OpenAI e Qwen. Cada fornecedor tem diferentes pontos fortes. Claude 3.5 Sonnet destaca-se pelo raciocínio complexo. A Nova Premier lida com tarefas multimodais. O Titan Embeddings optimiza a pesquisa semântica.
As ferramentas de avaliação incorporadas ajudam as equipas a comparar o desempenho, o custo e a precisão dos modelos. Isto transforma a seleção de modelos de adivinhação em decisões baseadas em dados.
Estrutura de preços: Como é que a Amazon Bedrock cobra
A Bedrock utiliza preços baseados em fichas com vários níveis de serviço. Os custos dependem do fornecedor do modelo específico, da modalidade e do nível de serviço selecionado.
A partir de março de 2026, a página oficial de preços apresenta vários escalões:
- Escalão standard: Preço base para inferência a pedido
- Escalão flexível: Preço-desempenho optimizado para casos de utilização específicos
- Nível de prioridade: Taxa normal mais prémio para um processamento mais rápido (até 25% melhor latência)
- Escalão reservado: Preços baseados em compromissos para cargas de trabalho previsíveis
A inferência em lote oferece um desconto de 50% em comparação com o preço on-demand para modelos de fundação selecionados. O preço é calculado por 1 milhão de tokens para entrada e saída.
| Modelo | Entrada (por 1M de fichas) | Produção (por 1M de fichas) |
|---|---|---|
| Claude Instant 1.2 | $0,0008 por 1K de tokens de entrada e $0,0024 por 1K de tokens de saída (ou $0,80 e $2,40 por milhão de tokens) | $0,0008 por 1K de tokens de entrada e $0,0024 por 1K de tokens de saída (ou $0,80 e $2,40 por milhão de tokens) |
| Claude 2.1 | $8.00 | $24.00 |
| Gemma 3 4B | $0.04 | $0.08 |
| Gemma 3 12B | $0.09 | $0.29 |
A página oficial de preços indica que as taxas variam consoante a região AWS. O Leste dos EUA (Virgínia), o Leste dos EUA (Ohio) e o Oeste dos EUA (Oregon) normalmente oferecem os preços mais competitivos. As operações de leitura e gravação em cache têm taxas separadas para modelos que suportam cache imediato.
Principais capacidades que diferenciam a Bedrock
Bases de conhecimento
As Bases de Conhecimento permitem que as aplicações liguem modelos de base a fontes de dados proprietárias. O serviço trata de todo o fluxo de trabalho Retrieval-Augmented Generation (RAG): ingestão de documentos a partir do S3, criação de embeddings vectoriais, armazenamento em bases de dados vectoriais e recuperação de contexto relevante para prompts.
Esta capacidade transforma as respostas genéricas da IA em respostas baseadas em dados, políticas ou documentação técnica específicos da empresa.
Agentes
Os Bedrock Agents orquestram tarefas de vários passos, dividindo os pedidos dos utilizadores, invocando APIs e executando acções. Um agente pode marcar compromissos, consultar bases de dados e efetuar cálculos - tudo através de instruções em linguagem natural.
Os agentes representam uma mudança da simples resposta a perguntas para a execução autónoma de tarefas. Alargam o que a IA generativa pode realizar sem código de orquestração personalizado.
Guarda-corpos
As barreiras de proteção aplicam políticas de segurança nas entradas e saídas do modelo. As equipas configuram filtros de conteúdo, restrições de tópicos e redação de informações sensíveis sem modificar o código da aplicação.
Isto é importante para os sectores regulamentados. Os serviços financeiros, os cuidados de saúde e as aplicações governamentais têm de impedir que os modelos gerem conteúdos inadequados ou divulguem dados protegidos. Os guardrails fornecem essa camada de controlo.
Personalização do modelo
As capacidades de afinação permitem às equipas adaptar os modelos de base utilizando os seus próprios conjuntos de dados. Isto melhora o desempenho de tarefas específicas do domínio sem ter de treinar modelos de raiz.
A personalização mantém o modelo sem servidor. As equipas carregam os dados de treino, configuram os hiperparâmetros e Bedrock trata do resto.
Amazon Bedrock vs Concorrentes
O mercado da plataforma de IA generativa concentra-se em três grandes players: Amazon Bedrock, Azure OpenAI Service e Google Vertex AI. Cada uma delas adota uma abordagem diferente.
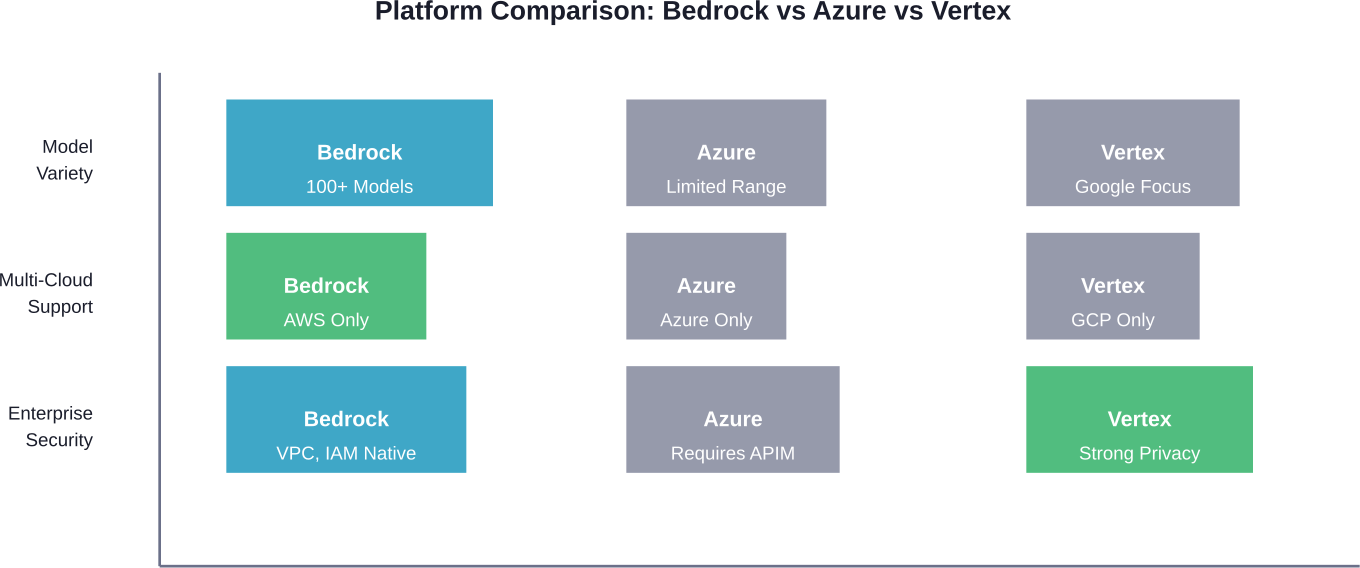
Bedrock enfatiza a diversidade de modelos. O Azure OpenAI concentra-se fortemente nos modelos OpenAI (GPT-4, GPT-3.5) com alternativas limitadas. O Google Vertex AI dá naturalmente prioridade aos modelos do próprio Google, como o PaLM e o Gemini.
A história da integração também é diferente. O Bedrock liga-se nativamente aos serviços AWS - S3, Lambda, IAM, CloudWatch. O Azure OpenAI integra-se no ecossistema da Microsoft. A Vertex AI funciona melhor no Google Cloud Platform.
As arquitecturas de segurança reflectem as filosofias das plataformas. O Bedrock usa pontos de extremidade VPC e funções de IAM sem serviços de gateway adicionais. As implementações do Azure requerem frequentemente a Gestão de API (APIM) para integração VNET, o que acrescenta custos horários e taxas de processamento de dados.
Conversa real: Quase 74% das organizações agora usam plataformas de IA baseadas em nuvem para reduzir os custos de infraestrutura e otimizar os recursos. O bloqueio da plataforma continua sendo uma preocupação, mas as estratégias de IA em várias nuvens permanecem complexas.
Aplicações do mundo real e casos de utilização
O Amazon Bedrock suporta diversas aplicações de IA generativa em todos os sectores. Os chatbots de serviço ao cliente utilizam modelos Claude para o tratamento de conversas com nuances. Os sistemas de geração de conteúdo aproveitam vários modelos para criar textos de marketing, descrições de produtos e documentação técnica.
A geração de código representa outro caso de utilização importante. As equipas de desenvolvimento utilizam o Bedrock para gerar automaticamente código padrão, escrever testes unitários e explicar bases de código complexas em linguagem natural.
As aplicações de processamento de documentos combinam bases de conhecimento com modelos de base para extrair informações de contratos, relatórios financeiros e documentos jurídicos. A arquitetura RAG baseia as respostas no conteúdo real do documento e não em alucinações de modelos.
De acordo com a AWS, empresas como Robinhood e Epsilon aproveitam o Bedrock para aplicativos de IA de produção. O serviço lida com cargas de trabalho voltadas para o cliente, onde a latência e a confiabilidade afetam diretamente os resultados dos negócios.

Ver como os dados da Amazon são realmente utilizados na prática
O Amazon Bedrock explica como o AWS lida com dados em grande escala e modelos de IA nos bastidores. Mas do lado do mercado, a maioria das decisões ainda se resume a dados mais simples - anúncios, cliques e vendas, e a forma como estão ligados. WisePPC funciona com essa camada.
Pega nos anúncios e nos dados de vendas da Amazon e coloca-os num único local para que possa ver o desempenho sem ter de juntar relatórios. Pode seguir a forma como as campanhas mudam ao longo do tempo, comparar resultados e ajustar diretamente as licitações ou os orçamentos, tudo com base no mesmo conjunto de dados e não em visualizações separadas. Explorar WisePPC para ver como os dados da Amazon são utilizados nas decisões quotidianas.
![]()
Como começar: Primeiros passos com Bedrock
A AWS fornece um caminho de início rápido para os novos utilizadores do Bedrock. A consola oferece uma interface Web para testar modelos sem escrever código. As equipas podem enviar pedidos, comparar resultados entre modelos e avaliar o desempenho antes de se comprometerem com a integração da API.
Para acesso programático, a API Bedrock suporta bibliotecas padrão do AWS SDK em várias linguagens - Python, JavaScript, Java, Go, C++. A autenticação utiliza credenciais IAM, o mesmo sistema de identidade que outros serviços AWS.
O acesso ao modelo requer uma ativação explícita. Nem todos os modelos da fundação estão disponíveis por padrão. As equipas solicitam o acesso através da consola Bedrock e a AWS fornece a capacidade com base na disponibilidade e na posição da conta.
A documentação oficial inclui exemplos de código para operações comuns: invocação de modelos, transmissão de respostas, gestão de conversas e implementação de fluxos de trabalho RAG. Estes exemplos aceleram o desenvolvimento inicial.
Limitações e considerações
O Amazon Bedrock funciona exclusivamente na infraestrutura AWS. As equipas empenhadas em estratégias multi-nuvem ou já investidas no Azure ou no GCP enfrentam desafios de migração. O serviço não oferece opções de implantação portáteis.
A disponibilidade regional varia. Nem todos os modelos estão acessíveis em todas as regiões do AWS. As diferenças de preços entre regiões podem afetar as estratégias de otimização de custos. As equipas devem verificar a disponibilidade do modelo na sua região de implementação preferida antes do planeamento da arquitetura.
Ocasionalmente, ocorrem restrições de capacidade do modelo durante períodos de elevada procura. O nível de prioridade ajuda, mas mesmo os níveis de serviço premium não podem garantir a disponibilidade instantânea durante picos de utilização extremos. Por vezes, os clientes empresariais esperam semanas pela aprovação da capacidade em regiões específicas.
Existem capacidades de afinação, mas não correspondem à profundidade da formação personalizada numa infraestrutura dedicada. As equipas com requisitos altamente especializados podem atingir limitações na profundidade de personalização do modelo.
Perguntas frequentes
Para que é utilizado exatamente o Amazon Bedrock?
O Amazon Bedrock é utilizado para criar aplicações de IA generativas como chatbots, geradores de conteúdos, analisadores de documentos e assistentes de código sem gerir infra-estruturas.
Quanto custa o Amazon Bedrock?
O preço baseia-se em fichas e varia consoante o modelo. Os custos dependem dos tokens de entrada/saída e do fornecedor escolhido, com descontos disponíveis para o processamento em lote.
Que modelos estão disponíveis no Amazon Bedrock?
A Bedrock oferece modelos de fornecedores como Anthropic, Amazon, Meta, Google, Mistral e outros, com disponibilidade dependente da região.
O Amazon Bedrock é o mesmo que o AWS SageMaker?
Não, o SageMaker concentra-se na formação de modelos personalizados, enquanto o Bedrock fornece acesso sem servidor a modelos pré-treinados para uma implementação mais rápida.
O Amazon Bedrock pode trabalhar com os meus dados privados?
Sim, pode ligar-se a fontes de dados privadas como o S3, mantendo os dados seguros na sua conta AWS.
Que sectores utilizam o Amazon Bedrock?
Os sectores incluem as finanças, os cuidados de saúde, o retalho, os meios de comunicação social, o desenvolvimento de software e a administração pública.
O Amazon Bedrock suporta o ajuste fino?
Sim, alguns modelos permitem um ajuste fino para personalizar os resultados utilizando os seus próprios dados.
Considerações finais
O Amazon Bedrock elimina as barreiras tradicionais à adoção de IA generativa. A arquitetura sem servidor e totalmente gerenciada permite que as equipes se concentrem na lógica do aplicativo em vez do gerenciamento da infraestrutura. O acesso a centenas de modelos de base líderes por meio de uma API unificada fornece flexibilidade à medida que a tecnologia de IA evolui.
Mas a plataforma reside no AWS. As estratégias de várias nuvens exigem camadas de arquitetura adicionais. As limitações regionais e as restrições de capacidade podem retardar as implantações. As equipas devem avaliar estas compensações em relação à simplicidade operacional que Bedrock proporciona.
Para organizações já comprometidas com a infraestrutura da AWS, o Bedrock oferece o caminho mais rápido da experimentação de IA para a implantação de produção. A combinação de diversidade de modelos, segurança empresarial e integração de serviços AWS cria uma plataforma atraente para escalar aplicativos de IA generativa.
Pronto para criar com IA generativa? Comece a explorar o Amazon Bedrock através da consola AWS, teste modelos para casos de utilização específicos e avalie a forma como a plataforma se adapta aos fluxos de trabalho existentes. A documentação oficial e os guias de início rápido fornecem caminhos de integração claros para equipas com qualquer nível de experiência.
 Não é necessário cartão de crédito
Não é necessário cartão de crédito