Comment tester vos produits de la bonne façon ?
Les tests A/B peuvent sembler techniques à première vue, mais il s'agit simplement d'un moyen d'arrêter de deviner et de commencer à apprendre à partir du comportement réel des clients. Au lieu de changer quelque chose et d'espérer que cela fonctionne, vous comparez deux versions et laissez les données vous indiquer ce qui améliore réellement les performances. Parfois, la différence est évidente. D'autres fois, les résultats vous surprennent, et c'est généralement là que se trouve la véritable source d'inspiration.
Pour les équipes de produits et les vendeurs, les tests ne visent plus à obtenir des résultats rapides, mais à renforcer la confiance dans les décisions. Une petite modification d'une image, d'un titre ou d'un message peut modifier la réaction des gens, mais sans test, il est presque impossible de savoir pourquoi. Une approche structurée des tests A/B permet de réduire les risques, de découvrir des modèles de comportement des clients et d'améliorer progressivement les résultats au fil du temps, sans perturber ce qui fonctionne déjà.
Ce que les tests A/B signifient réellement dans la pratique
Au quotidien, les tests A/B sont moins compliqués qu'il n'y paraît. Dans sa forme la plus simple, il s'agit d'une expérience contrôlée conçue pour répondre à une question : quelle version fonctionne le mieux pour les utilisateurs réels. Au lieu de changer quelque chose pour tout le monde en même temps, vous créez deux versions du même élément et divisez votre public entre elles. Un groupe voit la version originale, souvent appelée "contrôle", tandis que l'autre voit une version modifiée, appelée "variante". Tous les autres éléments restent inchangés afin que l'impact du changement unique puisse être observé clairement.
La fiabilité de cette approche réside dans le fait qu'elle élimine les opinions du processus. Les équipes prennent souvent des décisions sur la base de leur expérience, de leurs préférences ou de discussions internes, mais les clients ne réagissent pas toujours comme nous le souhaitons. Une image de produit qui semble plus propre à un concepteur peut sembler moins fiable à un acheteur. Une description plus courte peut sembler plus facile à lire mais laisser des questions importantes sans réponse. Les tests A/B remplacent les hypothèses par des comportements observables. Les utilisateurs votent par leurs actions plutôt que par leurs commentaires.
Un autre détail important est que les tests A/B ne consistent pas à deviner le gagnant à l'avance. Il s'agit de créer une comparaison équitable. Le trafic est généralement réparti de manière aléatoire afin que chaque version soit exposée à des types d'utilisateurs similaires. Au fil du temps, des schémas se dessinent. Si une version génère systématiquement plus de clics, d'achats ou d'engagement, il est peu probable que la différence soit accidentelle. C'est à ce moment-là que les équipes peuvent apporter des changements avec confiance plutôt qu'avec espoir.
Pourquoi les tests A/B sur les produits sont plus importants que jamais
Les produits ne se concurrencent plus seulement par leurs caractéristiques ou leur prix. Ils sont en concurrence sur la clarté, la confiance et la rapidité avec laquelle les utilisateurs comprennent la valeur. Dans un environnement où l'attention des clients est courte et où les attentes changent constamment, de petites améliorations peuvent faire une différence notable, et c'est précisément la raison pour laquelle les essais structurés sont devenus essentiels plutôt qu'optionnels.
L'évolution de l'environnement numérique exige une validation continue
Les environnements numériques ne sont pas immobiles. Les attentes des clients changent rapidement, les concurrents s'adaptent et les plateformes évoluent. Une page produit qui a bien fonctionné l'année dernière peut tranquillement perdre de son efficacité sans que personne ne s'en aperçoive immédiatement. Les petites baisses s'accumulent au fil du temps et les performances chutent rarement d'un seul coup. Le plus souvent, elle s'estompe progressivement au fur et à mesure que les attentes des utilisateurs changent. Les tests A/B permettent de détecter et de corriger ces évolutions lentes avant qu'elles ne deviennent des problèmes plus importants.
Les tests A/B évitent la stagnation et encouragent le progrès
Les tests A/B constituent une protection contre la stagnation. Au lieu d'attendre une baisse des performances, les équipes explorent activement les améliorations par le biais d'expériences contrôlées. Cette approche proactive crée une dynamique car l'optimisation fait partie du travail régulier plutôt que d'être un effort occasionnel de reconception. Même les gains mineurs sont importants. Lorsque de petites améliorations sont appliquées de manière cohérente aux images des produits, aux messages, à la mise en page ou à la présentation des prix, l'effet cumulatif peut être significatif au fil du temps.
Les données réduisent les frictions dans la prise de décision en équipe
Il existe également un avantage psychologique au sein des équipes qui passe souvent inaperçu. Les tests réduisent les frictions dans la prise de décision. Les discussions s'éloignent des goûts personnels et s'orientent vers des résultats mesurables. Lorsque les données remplacent les débats, les progrès tendent à s'accélérer car les décisions ne dépendent plus de la hiérarchie ou de l'opinion. Les équipes passent moins de temps à débattre de la direction à prendre et plus de temps à affiner ce qui fonctionne réellement pour les utilisateurs.
Ce qu'il faut tester en premier
Lorsque l'on découvre les tests A/B, on est souvent tenté de tout tester en même temps. Couleurs, polices, mises en page, messages, images. Le résultat est généralement plus bruyant qu'instructif. L'ordre des priorités est plus important que le volume d'expérimentation.
Un bon point de départ consiste à examiner les moments où les clients prennent des décisions. Ce sont des points où l'incertitude ou l'hésitation peuvent arrêter le progrès. Plus un élément est proche de ce moment de décision, plus sa valeur d'essai est élevée.
Éléments à fort impact à prendre en considération
- Images principales du produit ou visuels des héros
- Titres des produits et propositions de valeur
- Présentation des prix ou remises
- Libellé ou emplacement de l'appel à l'action
- Description des principales prestations
- Preuve sociale telle que des critiques ou des témoignages
Ces éléments façonnent la première impression et influencent la confiance. L'aspect visuel est important, mais la clarté l'est encore plus. Les clients doivent comprendre ce qu'est le produit, pourquoi il est important et ce qu'il faut faire ensuite. Les tests permettent d'affiner ce parcours.

WisePPC : Des analyses avancées pour guider votre stratégie de test A/B des produits
Au WisePPC, Pour nous, les tests A/B sont le prolongement naturel de l'analyse. Les tests ne fonctionnent que si vous comprenez clairement ce qui se passe avant et après un changement. C'est pourquoi notre plateforme s'attache à donner aux vendeurs une visibilité totale sur les performances publicitaires et commerciales en un seul endroit. Lorsque vous menez des expériences sur les listes de produits, les prix ou la structure des campagnes, vous devez voir comment ces changements affectent les résultats réels, et pas seulement les mesures de surface. En combinant les données historiques, le suivi des performances en temps réel et une segmentation détaillée, nous vous aidons à identifier si une variation améliore réellement les résultats ou si elle modifie simplement les chiffres de manière temporaire.
En pratique, cela signifie que nous permettons aux équipes de comparer les performances entre les campagnes, les placements et les périodes de temps sans perdre le contexte. Les données historiques à long terme permettent d'éviter les erreurs de test courantes, telles que l'évaluation prématurée des résultats ou l'absence de tendances saisonnières. Les analyses granulaires et le filtrage permettent d'isoler plus facilement ce qui a changé et pourquoi, tandis que les actions en bloc permettent des ajustements rapides une fois qu'une version gagnante a été identifiée. Au lieu de deviner quelle version est la plus performante, nous aidons les vendeurs à relier les décisions de test à un impact commercial mesurable, qu'il s'agisse d'un meilleur ROAS, d'une réduction des dépenses publicitaires inutiles ou d'une meilleure compréhension de ce qui génère réellement des conversions.
![]()
Comment réaliser un test A/B sans se tromper ?
Les tests A/B fonctionnent mieux lorsqu'ils suivent une séquence claire. De nombreuses équipes se lancent directement dans la création de variantes parce qu'elles ont l'impression de progresser. En réalité, la plupart des tests échouent avant même que l'expérience ne commence. La différence entre des résultats utiles et des données confuses se résume généralement à la préparation, à la clarté et à la patience.
Cette section présente l'ensemble du processus de manière pratique. Chaque étape s'appuyant sur la précédente, le fait de passer outre crée souvent des problèmes ultérieurs.
Étape 1 - Définir la notion de réussite
Avant de changer quoi que ce soit, il est important de comprendre pourquoi le test existe en premier lieu. Les tests A/B sans objectif clair se transforment en une activité sans direction. Vous risquez de vous retrouver avec des données, mais sans véritable réponse.
Un objectif de test solide est directement lié au comportement de l'utilisateur. Au lieu d'intentions vagues telles que l'amélioration des performances, l'objectif doit décrire un résultat spécifique que vous souhaitez influencer. Par exemple, un plus grand nombre d'achats effectués, un plus grand engagement avec les détails du produit ou moins d'utilisateurs qui abandonnent avant de passer à la caisse.
Ce qu'un objectif clair répond généralement
- Quelle action de l'utilisateur essayons-nous d'améliorer ?
- Où se situe le problème dans le voyage ?
- Comment le succès sera-t-il mesuré ?
Lorsque les objectifs sont clairs, l'analyse devient plus simple par la suite. Vous savez déjà quel indicateur est le plus important et pourquoi vous le mesurez.
Exemples d'objectifs de tests ciblés
- Augmenter le taux d'achat des produits en améliorant leur clarté
- Améliorer le taux de clics sur l'appel à l'action principal
- Réduire les abandons de panier lors de la validation de la commande
- Augmenter l'engagement avec des informations clés sur les produits
Plus l'objectif est clair, plus il est facile de concevoir un test pertinent.
Étape 2 - Transformer les observations en une hypothèse vérifiable
Une fois l'objectif défini, l'étape suivante consiste à expliquer pourquoi un changement pourrait fonctionner en premier lieu. C'est à ce stade que de nombreux tests prennent tout leur sens ou se transforment en expérimentation aléatoire. Une hypothèse donne une orientation au test. Elle relie ce que vous observez dans les données à un changement spécifique dont vous pensez qu'il pourrait améliorer le résultat.
Une hypothèse n'est pas une supposition ou une idée créative. Il s'agit d'une supposition structurée fondée sur l'observation. Quelque chose dans l'expérience actuelle ne fonctionne pas comme prévu, et l'hypothèse explique ce qui peut être à l'origine de cette friction. Par exemple, si les utilisateurs quittent systématiquement la page d'un produit au bout de quelques secondes, le problème n'est peut-être pas le prix ou la conception. Il se peut simplement que les visiteurs ne comprennent pas immédiatement pourquoi le produit est important pour eux. Dans ce cas, l'hypothèse pourrait être que l'amélioration de la clarté du titre ou du message d'ouverture aidera les utilisateurs à rester plus longtemps et à s'engager plus profondément.
Les hypothèses les plus utiles proviennent généralement de modèles plutôt que d'opinions. Les commentaires des clients révèlent souvent des confusions ou des informations manquantes. Les questions d'assistance mettent en évidence les domaines dans lesquels les attentes ne correspondent pas à la réalité. Les analyses peuvent montrer où les utilisateurs hésitent ou abandonnent complètement le processus. Même la comparaison de produits très performants avec des produits plus faibles peut révéler des différences de message ou de présentation qui méritent d'être testées. Ces signaux aident à transformer les essais en résolution de problèmes plutôt qu'en expérimentation pour le plaisir. Il est important que l'hypothèse reste ciblée. Chaque test doit viser à répondre à une question pertinente. Lorsque le champ d'application reste restreint, les résultats sont plus faciles à interpréter et les connaissances acquises peuvent être appliquées en toute confiance à des améliorations futures.
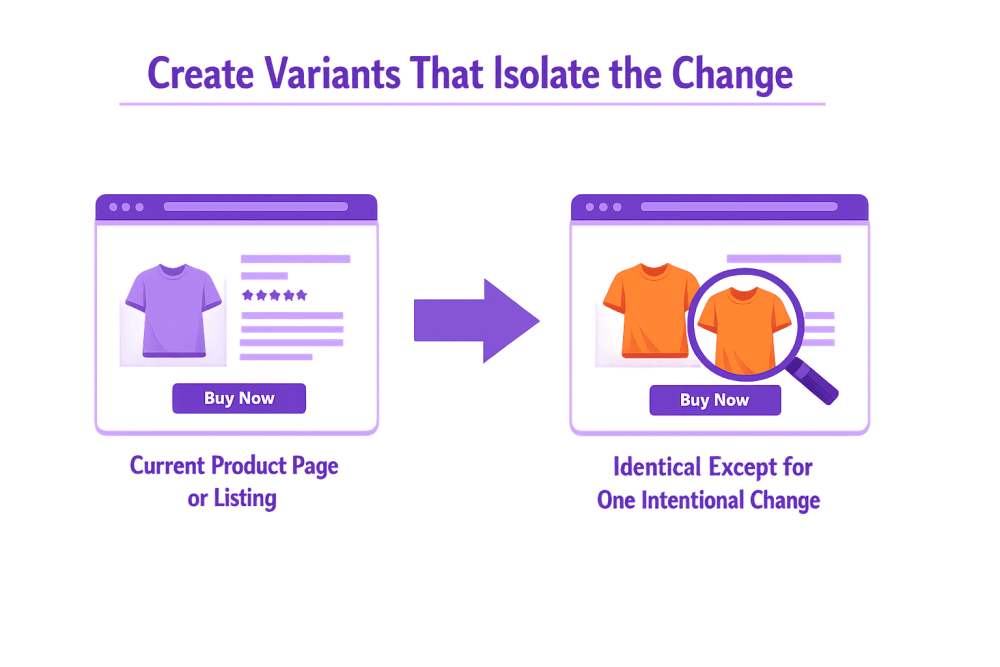
Étape 3 - Créer des variantes qui isolent le changement
C'est à ce stade que de nombreux tests A/B perdent tranquillement de leur valeur. Lorsque plusieurs améliorations semblent évidentes, l'instinct naturel est de tout mettre à jour en même temps. Une nouvelle image, un texte réécrit, une mise en page adaptée, peut-être même un changement de prix. Le problème, c'est qu'une fois que plusieurs éléments sont modifiés simultanément, les résultats ne sont plus clairs. Si les performances s'améliorent, vous ne pouvez pas expliquer avec certitude pourquoi cela s'est produit.
Un test A/B bien structuré est intentionnellement simple. L'objectif n'est pas de repenser l'ensemble de l'expérience, mais d'isoler une différence significative entre deux versions. Lorsqu'une seule variable change, la cause et l'effet deviennent visibles. Le résultat devient une connaissance utile plutôt qu'un résultat chanceux.
Version de contrôle - la page ou la liste actuelle du produit
La version de contrôle est la version existante que les utilisateurs voient déjà. Elle sert de base de comparaison car ses performances sont déjà connues. Rien n'est changé ici. Le fait de ne pas toucher à la version de contrôle permet de s'assurer que toute différence de performance provient de la nouvelle variation et non de facteurs externes.
Version variante - Identique à l'exception d'une modification intentionnelle
La version variante introduit un ajustement unique et délibéré basé sur l'hypothèse. Il peut s'agir d'une image de produit différente, d'un libellé de titre révisé ou d'un nouvel emplacement pour la preuve sociale. Tout le reste demeure inchangé afin que l'impact de ce seul changement puisse être mesuré avec précision. Le maintien de cette cohérence protège l'intégrité du test et facilite l'interprétation des résultats.
Lorsque les variantes sont créées de cette manière, les connaissances acquises deviennent réutilisables. Une modification réussie peut souvent être appliquée à d'autres produits ou pages, car vous comprenez ce qui a influencé le comportement de l'utilisateur, et pas seulement l'augmentation des performances.
Étape 4 - Laisser le test se dérouler suffisamment longtemps pour qu'il soit fiable
L'une des parties les plus difficiles des tests A/B est l'attente. Les premières données semblent souvent convaincantes, surtout lorsqu'une version commence à surpasser l'autre rapidement. Malheureusement, les premières tendances sont souvent temporaires.
Le comportement des utilisateurs change en fonction du moment, des sources de trafic et même du jour de la semaine. Une version qui fonctionne bien pendant une courte période peut ne pas fonctionner de la même manière au fil du temps.
Les raisons pour lesquelles les tests ont besoin de temps :
- Le comportement diffère en semaine et le week-end
- Les nouveaux visiteurs et ceux qui reviennent se comportent différemment
- Le trafic de la campagne fluctue
- Les variations aléatoires peuvent créer des pics à court terme
Mettre fin à un test trop tôt introduit un risque. Une décision prise sur la base de données incomplètes peut bloquer une version plus faible et annuler les améliorations précédentes. La patience permet de s'en prémunir.
Étape 5 - Aller au-delà d'un seul indicateur
Il est naturel de se concentrer sur la principale mesure liée à l'objectif. Cependant, les performances réelles sont rarement unidimensionnelles. Des améliorations dans un domaine peuvent entraîner des compromis inattendus dans d'autres domaines.
Par exemple, un message plus agressif peut augmenter le nombre de clics tout en réduisant la qualité des achats. L'engagement augmente, mais la valeur à long terme diminue. L'examen des mesures de soutien permet de mettre en évidence ces situations avant que les changements ne soient déployés à grande échelle.
Des mesures qui valent la peine d'être examinées parallèlement à l'objectif principal
- Taux de conversion
- Recettes par visiteur
- Ajouter au panier comportement
- Temps passé sur la page
- Taux de rebond ou de sortie
- Indicateurs de qualité de la clientèle
Une analyse équilibrée tient compte à la fois des signaux d'engagement et des résultats commerciaux. La version la plus performante n'est pas toujours celle qui enregistre le plus grand nombre de clics. C'est celle qui permet d'obtenir des résultats durables.
Les erreurs courantes à éviter en matière de tests A/B
La plupart des problèmes liés aux tests A/B ne sont pas dus à de mauvaises intentions ou à un manque d'efforts. Ils apparaissent généralement lorsque les équipes vont trop vite ou tentent de tirer des conclusions avant que les données ne soient prêtes. Les tests semblent simples en apparence, mais de petites erreurs de configuration ou d'interprétation peuvent conduire à des décisions qui nuisent discrètement aux performances au lieu de les améliorer. Comprendre où les choses tournent généralement mal permet de préserver l'utilité et la fiabilité des expériences.
Tester trop de changements à la fois
Il s'agit probablement du problème le plus courant, en particulier lorsque les équipes sont désireuses d'améliorer rapidement les résultats. Plusieurs éléments semblent faibles, et tout est donc mis à jour en même temps. La page est plus belle, les performances changent et tout le monde suppose que le test a fonctionné. Le problème est que personne ne sait quel changement a réellement fait la différence.
Lorsque plusieurs variables évoluent ensemble, il devient impossible de tirer des enseignements du résultat. Vous pouvez accidentellement conserver les modifications qui ont nui aux performances tout en supprimant celles qui les ont favorisées. Au fil du temps, cela crée des résultats incohérents et rend les tests futurs plus difficiles.
Les tests A/B donnent les meilleurs résultats lorsque chaque expérience répond à une question claire. Un changement, une comparaison, une conclusion.
Mettre fin aux tests trop tôt
Les premières données peuvent être convaincantes. Une variante montre une amélioration après quelques jours et la tentation de déclarer un vainqueur devient forte. Le problème est que les premiers résultats sont souvent instables. Les schémas de trafic évoluent au cours de la semaine, les campagnes changent et le comportement des utilisateurs varie en fonction du moment.
Arrêter un test trop tôt augmente le risque de choisir un faux gagnant. Ce qui ressemble à une amélioration peut n'être qu'une fluctuation à court terme. En laissant suffisamment de temps pour que le comportement se normalise, on s'assure que le résultat reflète une performance réelle plutôt qu'une coïncidence.
La patience n'est pas du temps perdu. Elle vous évite de mettre en œuvre des changements qui devront être annulés par la suite.

Optimiser pour le mauvais indicateur
Toutes les améliorations ne sont pas réellement des améliorations. Il arrive qu'un test augmente l'activité sans améliorer les résultats importants pour l'entreprise. Par exemple, un message plus agressif peut augmenter le nombre de clics tout en attirant des acheteurs moins sérieux, ce qui se traduit par une baisse du chiffre d'affaires global ou de la fidélisation.
Cela se produit généralement lorsque les équipes se concentrent sur des mesures faciles à mettre en œuvre plutôt que sur des mesures significatives. Les indicateurs doivent toujours être liés à l'objectif réel du produit ou de la campagne.
Les exemples les plus courants sont les suivants :
- Augmenter le taux de clics alors que le taux d'achat diminue
- Améliorer le nombre d'ajouts au panier sans améliorer les commandes terminées
- Réduire la friction des formulaires mais diminuer la qualité des prospects
- Augmenter le temps d'engagement sans augmenter les conversions
L'examen des paramètres de soutien parallèlement à l'objectif principal permet d'éviter ce genre de situation.
Partir du principe qu'un seul résultat convient à tous les publics
Une autre erreur fréquente consiste à supposer qu'une version gagnante fonctionne aussi bien pour tout le monde. En réalité, les différents segments du public se comportent souvent différemment. Les nouveaux visiteurs peuvent avoir besoin de plus d'explications, tandis que les clients fidèles préfèrent la rapidité et la familiarité. Les utilisateurs de téléphones mobiles peuvent réagir différemment des utilisateurs d'ordinateurs de bureau.
Ignorer ces différences peut cacher des informations précieuses. Il arrive qu'une variante perdante dans l'ensemble soit exceptionnellement performante pour un segment spécifique. Reconnaître ces tendances peut conduire à des améliorations plus ciblées plutôt qu'à un changement universel.
Conclusion
Les tests A/B sont souvent décrits comme une tactique, mais dans la pratique, ils deviennent une façon d'envisager l'amélioration. Au lieu de procéder à des changements sur la base de l'instinct ou d'un débat interne, vous donnez aux utilisateurs réels la possibilité de s'exprimer sur la décision. Parfois, les résultats confirment ce que vous attendiez. D'autres fois, ils remettent en question des hypothèses dont vous n'aviez même pas conscience. Dans les deux cas, le produit progresse.
Ce qui compte le plus, c'est la cohérence. Un test ne transformera pas les performances du jour au lendemain, et c'est tout à fait normal. La valeur réelle apparaît au fil du temps, au fur et à mesure que les petites informations s'accumulent. Vous commencez à comprendre comment les clients interprètent votre message, ce qui renforce la confiance et où se situent les frictions dans le processus d'achat. Les décisions deviennent plus sereines, les changements plus sûrs et les progrès plus prévisibles.
S'il est une chose dont il faut se souvenir, c'est que l'essai ne consiste pas à rechercher la perfection. Les produits évoluent, le public change et de nouvelles idées apparaissent toujours. Les tests A/B vous offrent simplement un moyen fiable de vous adapter sans avoir à deviner. Commencez par une question claire, testez-la honnêtement et laissez les résultats guider l'étape suivante.
FAQ
Combien de temps un test A/B doit-il durer avant de désigner le vainqueur ?
Il n'existe pas de durée universelle, car elle dépend du volume de trafic et du nombre de conversions générées. En général, un test doit durer suffisamment longtemps pour saisir le comportement normal de l'utilisateur au fil des jours et des modèles de trafic. Il est donc préférable d'attendre que les résultats se stabilisent plutôt que de réagir aux premières tendances.
Les petits changements peuvent-ils vraiment faire la différence dans les tests A/B ?
Oui, et c'est souvent de là que viennent les améliorations surprenantes. Une image différente, un titre plus clair ou un meilleur emplacement des informations clés peuvent modifier la rapidité avec laquelle les utilisateurs comprennent un produit. Ces changements peuvent sembler mineurs en interne, mais ils peuvent avoir une incidence considérable sur la manière dont les clients prennent leurs décisions.
Que dois-je tester en premier si je suis novice en matière de tests A/B ?
Il est généralement judicieux de commencer par les éléments qui influencent directement les décisions d'achat. Les images de produits, les propositions de valeur et les appels à l'action ont généralement un impact plus fort que les ajustements purement visuels. Tester les éléments les plus proches de la conversion permet d'obtenir des résultats plus clairs dès le début.
Un test A/B peut-il échouer ?
Absolument, et cela ne signifie pas que le test a été inutile. Un résultat qui ne montre aucune amélioration fournit tout de même des informations. Il vous indique qu'une hypothèse particulière était incorrecte, ce qui permet d'éviter des erreurs plus importantes par la suite. Au fil du temps, ces enseignements permettent d'affiner les expériences futures.
Ai-je besoin d'outils spéciaux pour effectuer des tests A/B de manière efficace ?
Les outils facilitent le suivi et l'analyse, en particulier lorsque les essais deviennent plus fréquents, mais l'idée de base ne dépend pas d'un logiciel complexe. Ce qui importe le plus, c'est d'avoir des objectifs clairs, d'isoler correctement les changements et d'analyser soigneusement les résultats. La technologie soutient le processus, mais c'est la discipline qui le fait fonctionner.
Rejoignez la bêta de WisePPC et bénéficiez d'un accès exclusif
WisePPC est maintenant en version bêta - et nous invitons un nombre limité d'utilisateurs à nous rejoindre. En tant que bêta-testeur, vous bénéficierez d'un accès gratuit, d'avantages à vie et d'une chance de contribuer à l'élaboration du produit - d'un Amazon Ads Verified Partner vous pouvez faire confiance.
 Aucune carte de crédit n'est requise
Gratuit en version bêta et mois supplémentaire gratuit après la sortie de la version bêta
25% à vie - offre bêta limitée
Accédez aux mesures que les publicités d'Amazon ne vous montrent pas
Participez à l'élaboration du produit grâce à vos commentaires
Aucune carte de crédit n'est requise
Gratuit en version bêta et mois supplémentaire gratuit après la sortie de la version bêta
25% à vie - offre bêta limitée
Accédez aux mesures que les publicités d'Amazon ne vous montrent pas
Participez à l'élaboration du produit grâce à vos commentaires
