Como fazer o teste A/B dos seus produtos da forma correta
Os testes A/B parecem técnicos à primeira vista, mas na sua essência são simplesmente uma forma de deixar de adivinhar e começar a aprender com o comportamento real dos clientes. Em vez de alterar algo e esperar que funcione, compara duas versões e deixa que os dados lhe digam o que realmente melhora o desempenho. Por vezes, a diferença é óbvia. Outras vezes, os resultados surpreendem-no, e é aí que reside a verdadeira perceção.
Para as equipas de produtos e para os vendedores, os testes não têm tanto a ver com a procura de ganhos rápidos, mas sim com o reforço da confiança nas decisões. Uma pequena alteração a uma imagem, título ou mensagem pode mudar a forma como as pessoas reagem, mas sem testes é quase impossível saber porquê. Uma abordagem de teste A/B estruturada ajuda a reduzir o risco, a descobrir padrões no comportamento do cliente e a melhorar gradualmente os resultados ao longo do tempo sem perturbar o que já funciona.
O que significa realmente o teste A/B na prática
No trabalho quotidiano, o teste A/B é menos complicado do que parece. Na sua forma mais simples, é uma experiência controlada concebida para responder a uma pergunta: qual a versão que funciona melhor para os utilizadores reais. Em vez de alterar algo para todos de uma só vez, cria duas versões do mesmo elemento e divide o seu público entre elas. Um grupo vê a versão original, frequentemente designada por controlo, enquanto o outro vê uma versão modificada, designada por variante. Tudo o resto permanece igual para que o impacto de uma única alteração possa ser observado claramente.
O que torna esta abordagem fiável é o facto de eliminar a opinião do processo. As equipas tomam frequentemente decisões com base na experiência, preferências ou discussões internas, mas os clientes nem sempre respondem da forma que esperamos. Uma imagem de produto que parece mais limpa para um designer pode parecer menos fiável para um comprador. Uma descrição mais curta pode parecer mais fácil de ler, mas deixa perguntas importantes sem resposta. Os testes A/B substituem as suposições por comportamentos observáveis. Os utilizadores votam através das suas acções e não do seu feedback.
Outro pormenor importante é que o teste A/B não consiste em adivinhar antecipadamente o vencedor. Trata-se de criar uma comparação justa. O tráfego é normalmente dividido de forma aleatória para que cada versão seja exposta a tipos de utilizadores semelhantes. Com o tempo, surgem padrões. Se uma das versões conduzir consistentemente a mais cliques, compras ou envolvimento, é pouco provável que a diferença seja acidental. É nessa altura que as equipas podem fazer alterações com confiança em vez de esperança.
Porque é que os testes A/B de produtos são mais importantes do que nunca
Os produtos já não competem apenas em termos de caraterísticas ou preço. Competem pela clareza, pela confiança e pela rapidez com que os utilizadores compreendem o valor. Num ambiente em que a atenção do cliente é curta e as expectativas mudam constantemente, pequenas melhorias podem fazer uma diferença notável, e é exatamente por isso que os testes estruturados se tornaram essenciais e não opcionais.
Ambientes digitais em constante mudança exigem validação contínua
Os ambientes digitais não param. As expectativas dos clientes mudam rapidamente, os concorrentes adaptam-se e as plataformas evoluem. Uma página de produto que teve um bom desempenho no ano passado pode perder eficácia sem que ninguém se aperceba imediatamente. Os pequenos declínios agravam-se com o tempo e o desempenho raramente cai de uma só vez. Mais frequentemente, diminui gradualmente à medida que as expectativas dos utilizadores se alteram. Os testes A/B ajudam a detetar e corrigir estas mudanças lentas antes que se tornem problemas maiores.
Os testes A/B evitam a estagnação e incentivam o progresso
Os testes A/B actuam como uma salvaguarda contra a estagnação. Em vez de esperar por quedas de desempenho, as equipas exploram ativamente as melhorias através de experiências controladas. Esta abordagem proactiva cria uma dinâmica porque a otimização passa a fazer parte do trabalho regular e não de um esforço ocasional de remodelação. Mesmo os pequenos ganhos são importantes. Quando pequenas melhorias são aplicadas de forma consistente em imagens de produtos, mensagens, layout ou apresentação de preços, o efeito cumulativo pode ser significativo ao longo do tempo.
Os dados reduzem a fricção na tomada de decisões da equipa
Há também um benefício psicológico dentro das equipas que muitas vezes passa despercebido. Os testes reduzem o atrito na tomada de decisões. As discussões afastam-se dos gostos pessoais e aproximam-se de resultados mensuráveis. Quando os dados substituem o debate, o progresso tende a acelerar porque as decisões já não dependem da hierarquia ou da opinião. As equipas passam menos tempo a discutir sobre a direção a seguir e mais tempo a aperfeiçoar o que realmente funciona para os utilizadores.
O que deve testar primeiro
Quando as pessoas descobrem os testes A/B pela primeira vez, é frequente a tentação de testar tudo ao mesmo tempo. Cores, tipos de letra, layouts, mensagens, imagens. O resultado é, normalmente, mais ruído do que informação. A definição de prioridades é mais importante do que o volume de experiências.
Um bom ponto de partida é analisar os momentos em que os clientes tomam decisões. Estes são os pontos em que a incerteza ou a hesitação podem travar o progresso. Quanto mais próximo um elemento estiver desse momento de decisão, maior será o seu valor de teste.
Elementos de grande impacto a considerar
- Imagens principais do produto ou imagens de herói
- Títulos de produtos e propostas de valor
- Apresentação de preços ou descontos
- Texto ou colocação do apelo à ação
- Descrições das principais prestações
- Prova social, como críticas ou testemunhos
Estes elementos moldam as primeiras impressões e influenciam a confiança. O polimento visual é importante, mas a clareza é ainda mais importante. Os clientes precisam de compreender o que é o produto, a sua importância e o que fazer a seguir. Os testes ajudam a aperfeiçoar esse caminho.

WisePPC: Análise avançada para orientar a sua estratégia de teste A/B de produtos
Em WisePPC, Para nós, os testes A/B são uma extensão natural da análise. Os testes só funcionam quando se compreende claramente o que está a acontecer antes e depois de uma alteração. É por isso que a nossa plataforma se concentra em dar aos vendedores visibilidade total do desempenho da publicidade e das vendas num único local. Quando efectua experiências em listagens de produtos, preços ou estrutura de campanhas, precisa de ver como essas alterações afectam os resultados reais e não apenas as métricas superficiais. Ao combinar dados históricos, controlo de desempenho em tempo real e segmentação detalhada, ajudamos a identificar se uma variação melhora verdadeiramente os resultados ou se apenas altera temporariamente os números.
Na prática, isto significa que permitimos às equipas comparar o desempenho entre campanhas, canais e períodos de tempo sem perder o contexto. Os dados históricos a longo prazo ajudam a evitar erros de teste comuns, como julgar os resultados demasiado cedo ou não perceber padrões sazonais. A análise granular e a filtragem facilitam a identificação do que mudou e porquê, enquanto as acções em massa permitem ajustes rápidos quando é identificada uma versão vencedora. Em vez de tentar adivinhar qual a versão com melhor desempenho, concentramo-nos em ajudar os vendedores a associar as decisões de teste a um impacto comercial mensurável, quer se trate de um ROAS melhorado, de uma redução do desperdício de gastos com publicidade ou de uma compreensão mais clara do que realmente gera conversões.
![]()
Como efetuar um teste A/B sem adivinhações
Os testes A/B funcionam melhor quando seguem uma sequência clara. Muitas equipas começam logo a criar variações porque isso parece um progresso. Na realidade, a maioria dos testes falhados acontece antes mesmo de a experiência começar. A diferença entre resultados úteis e dados confusos resume-se normalmente à preparação, clareza e paciência.
Esta secção percorre todo o processo de uma forma prática. Cada passo baseia-se no anterior, pelo que saltar à frente cria frequentemente mais problemas mais tarde.
Passo 1 - Definir o que significa realmente sucesso
Antes de alterar seja o que for, é importante compreender a razão da existência do teste. Um teste A/B sem um objetivo claro transforma-se numa atividade sem direção. Pode acabar com dados, mas sem uma resposta concreta.
Um objetivo de teste forte está diretamente relacionado com o comportamento do utilizador. Em vez de intenções vagas como melhorar o desempenho, o objetivo deve descrever um resultado específico que pretende influenciar. Por exemplo, mais compras concluídas, maior envolvimento com os detalhes do produto ou menos utilizadores que abandonem o site antes da finalização da compra.
O que um objetivo claro normalmente responde
- Que ação do utilizador estamos a tentar melhorar
- Em que ponto do trajeto ocorre o problema
- Como será medido o sucesso
Quando os objectivos são claros, a análise torna-se mais simples mais tarde. Já sabe qual a métrica mais importante e porque a está a medir.
Exemplos de objectivos de testes orientados
- Aumentar a taxa de compra de produtos, melhorando a clareza do produto
- Melhorar a taxa de cliques no principal convite à ação
- Reduzir o abandono do carrinho durante o checkout
- Aumentar o envolvimento com as principais informações sobre os produtos
Quanto mais claro for o objetivo, mais fácil se torna conceber um teste com significado.
Passo 2 - Transformar as observações numa hipótese testável
Uma vez definido o objetivo, o passo seguinte é explicar porque é que uma mudança pode funcionar. É aqui que muitos testes se tornam significativos ou se transformam em experiências aleatórias. Uma hipótese dá uma direção ao teste. Liga o que se está a ver nos dados a uma alteração específica que se acredita poder melhorar o resultado.
Uma hipótese não é um palpite ou uma ideia criativa. É uma suposição estruturada baseada na observação. Algo na experiência atual não está a funcionar como esperado e a hipótese explica o que pode estar a causar esse atrito. Por exemplo, se os utilizadores abandonam sistematicamente a página de um produto em poucos segundos, o problema pode não ser o preço ou o design. Pode ser simplesmente o facto de os visitantes não compreenderem imediatamente porque é que o produto é importante para eles. Nesse caso, a hipótese pode ser que melhorar a clareza do título ou da mensagem de abertura ajudará os utilizadores a permanecerem mais tempo e a envolverem-se mais profundamente.
As hipóteses mais úteis provêm geralmente de padrões e não de opiniões. As análises dos clientes revelam frequentemente confusão ou informações em falta. As perguntas de apoio destacam áreas em que as expectativas não correspondem à realidade. A análise pode mostrar onde os utilizadores hesitam ou abandonam completamente o processo. Mesmo a comparação de produtos de elevado desempenho com produtos mais fracos pode revelar diferenças nas mensagens ou na apresentação que valem a pena ser testadas. Estes sinais ajudam a transformar os testes na resolução de problemas e não na experimentação por si só. É importante manter a hipótese focada. Cada teste deve ter como objetivo responder a uma pergunta significativa. Quando o âmbito se mantém restrito, o resultado torna-se mais fácil de interpretar e a informação obtida pode ser aplicada com confiança a melhorias futuras.
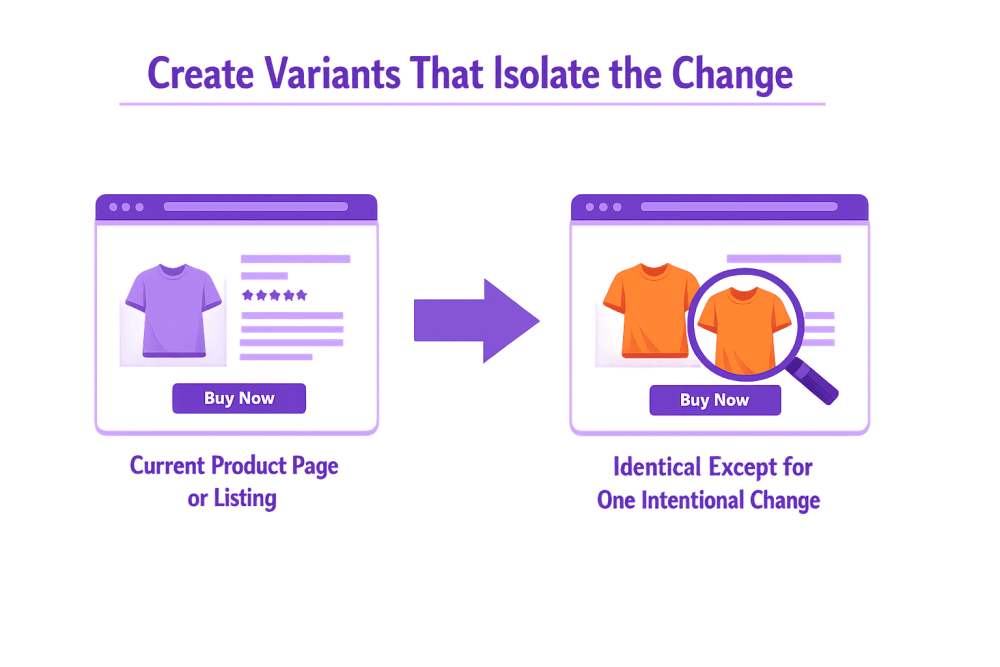
Etapa 3 - Criar variantes que isolem a alteração
Esta é a fase em que muitos testes A/B perdem o seu valor. Quando várias melhorias parecem óbvias, o instinto natural é atualizar tudo de uma vez. Uma nova imagem, um texto reescrito, um layout ajustado, talvez até alterações de preços. O problema é que quando vários elementos mudam em conjunto, os resultados deixam de ser claros. Se o desempenho melhorar, não é possível explicar com segurança porque é que isso aconteceu.
Um teste A/B bem estruturado mantém as coisas intencionalmente simples. O objetivo não é redesenhar toda a experiência, mas isolar uma diferença significativa entre duas versões. Quando apenas uma variável muda, a causa e o efeito tornam-se visíveis. O resultado torna-se um conhecimento útil em vez de um resultado de sorte.
Versão de controlo - a página ou listagem atual do produto
A versão de controlo é a versão existente que os utilizadores já vêem. Serve de base de comparação porque o seu desempenho já é conhecido. Nada é alterado aqui. Manter o controlo inalterado garante que qualquer diferença no desempenho provém da nova variação e não de factores externos.
Versão Variante - Idêntica exceto por uma alteração intencional
A versão variante introduz um ajuste único e deliberado com base na hipótese. Pode ser uma imagem diferente do produto, uma redação revista do título ou um novo posicionamento para prova social. Tudo o resto permanece igual para que o impacto dessa única alteração possa ser medido com exatidão. Manter esta consistência protege a integridade do teste e torna o resultado mais fácil de interpretar.
Quando as variantes são criadas desta forma, a informação obtida torna-se reutilizável. Uma alteração bem sucedida pode muitas vezes ser aplicada a outros produtos ou páginas porque se compreende o que influenciou o comportamento do utilizador e não apenas que o desempenho aumentou.
Passo 4 - Deixe o teste decorrer o tempo suficiente para ser fiável
Uma das partes mais difíceis dos testes A/B é esperar. Os primeiros dados parecem muitas vezes convincentes, especialmente quando uma versão começa rapidamente a superar a outra. Infelizmente, as tendências iniciais são muitas vezes temporárias.
O comportamento do utilizador muda consoante a hora, as fontes de tráfego e até o dia da semana. Uma versão com bom desempenho durante um curto período de tempo pode não ter o mesmo desempenho ao longo do tempo.
As razões pelas quais os testes precisam de tempo:
- O comportamento durante a semana e o fim de semana é diferente
- Os visitantes novos e os que regressam têm comportamentos diferentes
- O tráfego da campanha flutua
- A variação aleatória pode criar picos de curto prazo
Terminar um teste demasiado cedo introduz riscos. Uma decisão tomada com base em dados incompletos pode bloquear uma versão mais fraca e anular as melhorias anteriores. A paciência protege contra isto.
Etapa 5 - Olhar para além de uma única métrica
É natural que nos concentremos na métrica principal associada ao objetivo. No entanto, o desempenho real raramente é unidimensional. As melhorias numa área podem criar compensações inesperadas noutras áreas.
Por exemplo, uma mensagem mais agressiva pode aumentar os cliques, mas reduzir a qualidade da compra. O envolvimento aumenta, mas o valor a longo prazo diminui. A análise das métricas de apoio ajuda a revelar estas situações antes de as alterações serem implementadas de forma generalizada.
Métricas que merecem ser analisadas juntamente com o objetivo principal
- Taxa de conversão
- Receitas por visitante
- Comportamento de adicionar ao carrinho
- Tempo passado na página
- Taxas de rejeição ou de saída
- Indicadores de qualidade do cliente
Uma análise equilibrada considera tanto os sinais de envolvimento como os resultados comerciais. A versão com melhor desempenho nem sempre é a que tem mais cliques. É aquela que suporta resultados sustentáveis.
Erros comuns de teste A/B a evitar
A maioria dos problemas dos testes A/B não resulta de más intenções ou de falta de esforço. Normalmente, surgem quando as equipas avançam demasiado depressa ou tentam forçar conclusões antes de os dados estarem prontos. À primeira vista, os testes parecem simples, mas pequenos erros de configuração ou interpretação podem levar a decisões que prejudicam silenciosamente o desempenho em vez de o melhorar. Compreender onde é que as coisas normalmente correm mal ajuda a manter as experiências úteis e fiáveis.
Testar demasiadas alterações de uma só vez
Este é provavelmente o problema mais comum, especialmente quando as equipas estão ansiosas por melhorar os resultados rapidamente. Vários elementos parecem fracos, por isso tudo é atualizado ao mesmo tempo. A página fica com melhor aspeto, o desempenho muda e todos assumem que o teste funcionou. O problema é que ninguém sabe qual a alteração que efetivamente fez a diferença.
Quando várias variáveis se movem em conjunto, torna-se impossível aprender com o resultado. Pode acidentalmente manter as alterações que prejudicam o desempenho e remover as que o ajudam. Com o tempo, isso cria resultados inconsistentes e dificulta os testes futuros.
Os testes A/B funcionam melhor quando cada experiência responde a uma pergunta clara. Uma alteração, uma comparação, uma conclusão.
Terminar os testes demasiado cedo
Os primeiros dados podem ser convincentes. Uma variante mostra melhorias após alguns dias e a tentação de declarar um vencedor torna-se forte. O problema é que os primeiros resultados são frequentemente instáveis. Os padrões de tráfego mudam ao longo da semana, as campanhas mudam e o comportamento dos utilizadores varia consoante o momento.
Parar um teste demasiado cedo aumenta a possibilidade de escolher um falso vencedor. O que parece ser uma melhoria pode ser simplesmente uma flutuação de curto prazo. Permitir tempo suficiente para que o comportamento se normalize ajuda a garantir que o resultado reflecte o desempenho real e não uma coincidência.
Aqui, a paciência não é um tempo perdido. Protege-o de introduzir alterações que mais tarde terão de ser anuladas.

Otimizar para a métrica errada
Nem todas as melhorias são efetivamente uma melhoria. Por vezes, um teste aumenta a atividade sem melhorar os resultados importantes para a empresa. Por exemplo, uma mensagem mais agressiva pode aumentar os cliques e, ao mesmo tempo, atrair compradores menos sérios, o que leva a uma diminuição das receitas ou da retenção.
Isto acontece normalmente quando as equipas se concentram em métricas fáceis em vez de métricas significativas. As métricas devem estar sempre relacionadas com o verdadeiro objetivo do produto ou da campanha.
Exemplos comuns incluem:
- Aumento da taxa de cliques enquanto a taxa de compra diminui
- Melhorar o número de adições ao carrinho sem melhorar as encomendas concluídas
- Reduzir a fricção dos formulários mas diminuir a qualidade dos contactos
- Aumentar o tempo de envolvimento sem aumentar as conversões
Analisar as métricas de apoio juntamente com o objetivo principal ajuda a evitar estas situações.
Assumir que um resultado se adequa a todos os públicos
Outro erro frequente é assumir que uma versão vencedora funciona igualmente bem para toda a gente. Na realidade, os diferentes segmentos de público comportam-se muitas vezes de forma diferente. Os novos visitantes podem precisar de mais explicações, enquanto os clientes que regressam preferem rapidez e familiaridade. Os utilizadores de telemóveis podem reagir de forma diferente dos utilizadores de computadores.
Ignorar estas diferenças pode esconder informações valiosas. Por vezes, uma variante perdedora tem um desempenho excecionalmente bom para um segmento específico. O reconhecimento destes padrões pode conduzir a melhorias mais direcionadas em vez de uma alteração universal.
Conclusão
Os testes A/B são frequentemente descritos como uma tática, mas na prática tornam-se uma forma de pensar sobre a melhoria. Em vez de fazer alterações com base no instinto ou no debate interno, dá-se aos utilizadores reais uma voz na decisão. Por vezes, os resultados confirmam o que se esperava. Outras vezes, desafiam suposições que nem sequer se apercebeu que estava a fazer. Ambos os resultados fazem o produto avançar.
O mais importante é a consistência. Um teste não transformará o desempenho de um dia para o outro, e isso é perfeitamente normal. O verdadeiro valor surge ao longo do tempo, à medida que se acumulam pequenas informações. Começa a compreender como os clientes interpretam as suas mensagens, o que gera confiança e onde surgem fricções no processo de compra. As decisões tornam-se mais calmas, as mudanças tornam-se mais seguras e o progresso torna-se mais previsível.
Se há uma coisa que vale a pena recordar, é que os testes não são uma questão de perseguir a perfeição. Os produtos evoluem, as audiências mudam e surgem sempre novas ideias. Os testes A/B dão-lhe simplesmente uma forma fiável de se adaptar sem ter de adivinhar. Comece com uma pergunta clara, teste-a honestamente e deixe que os resultados orientem o passo seguinte.
FAQ
Quanto tempo deve durar um teste A/B antes de escolher um vencedor?
Não existe uma cronologia universal porque depende do volume de tráfego e do número de conversões geradas. Em geral, um teste deve durar o tempo suficiente para captar o comportamento normal do utilizador em diferentes dias e padrões de tráfego. Terminar um teste demasiado cedo leva frequentemente a conclusões enganadoras, pelo que é melhor esperar até que os resultados estabilizem em vez de reagir a tendências iniciais.
As pequenas alterações podem realmente fazer a diferença nos testes A/B?
Sim, e é frequentemente daí que surgem melhorias surpreendentes. Uma imagem diferente, um título mais claro ou uma melhor colocação de informações importantes podem alterar a rapidez com que os utilizadores compreendem um produto. Estas alterações podem parecer insignificantes a nível interno, mas podem afetar significativamente a forma como os clientes tomam decisões.
O que devo testar primeiro se sou novo no domínio dos testes A/B?
Normalmente, faz sentido começar pelos elementos que influenciam diretamente as decisões de compra. As imagens dos produtos, as propostas de valor e os apelos à ação tendem a ter um impacto mais forte do que os ajustes puramente visuais. Testar as áreas mais próximas da conversão ajuda a produzir resultados mais claros numa fase inicial.
É possível que um teste A/B falhe?
Absolutamente, e isso não significa que o teste tenha sido desperdiçado. Um resultado que não revela qualquer melhoria continua a fornecer informações. Diz-lhe que um determinado pressuposto estava incorreto, o que evita erros maiores mais tarde. Com o tempo, estas aprendizagens ajudam a aperfeiçoar as experiências futuras.
Preciso de ferramentas especiais para efetuar testes A/B de forma eficaz?
As ferramentas ajudam no controlo e na análise, especialmente à medida que os testes se tornam mais frequentes, mas a ideia central não depende de software complexo. O mais importante é ter objectivos claros, isolar adequadamente as alterações e analisar cuidadosamente os resultados. A tecnologia apoia o processo, mas é a disciplina que o faz funcionar.
Junte-se ao WisePPC Beta e obtenha benefícios de acesso exclusivos
O WisePPC está agora em fase beta - e estamos a convidar um número limitado de primeiros utilizadores a juntarem-se a nós. Como utilizador beta, terá acesso gratuito, vantagens vitalícias e a oportunidade de ajudar a moldar o produto - desde um Parceiro verificado da Amazon Ads em que pode confiar.
 Não é necessário cartão de crédito
Gratuito na versão beta e mês extra gratuito após o lançamento
25% off for life - oferta beta limitada
Acesso a métricas que o Amazon Ads não lhe mostra
Participe na conceção do produto com o seu feedback
Não é necessário cartão de crédito
Gratuito na versão beta e mês extra gratuito após o lançamento
25% off for life - oferta beta limitada
Acesso a métricas que o Amazon Ads não lhe mostra
Participe na conceção do produto com o seu feedback
